Google Topics API: 11 things I learned from the documentation
FLoC is dead. Long live Google Topics API.
Google has replaced its much-hated Federated Learning of Crowds privacy-safe ad targeting proposal with the new Topics API. Google Topics are intended to enable relevant advertising without invasive tracking.
There are four key types of data marketers use to try to deliver relevant ads:
- Contextual data: an ad is like the content that surrounds it in some way, so people who have sought out that content are likely to be also interested in the ad. (Sometimes tangential insights play here, like scuba divers may tend to take beach vacations, or bikers may tend to like dive bars.)
- Intent data: an ad is relevant to a search query that a person has recently entered, which means it should theoretically be something that they are interested in.
- Behavioral data: an ad is relevant to things a person has recently done and places (virtual places likes apps and websites included) that they have been, so it should be relevant to things they might also like.
- Demographic data: an ad is broadly relevant to to a particular demographic based on location, age, socioeconomic factors, and is therefore hopefully relevant to a person viewing it.
The new Topics API essentially is trying to achieve privacy-safe behavioral data. Traditionally, behavioral data has been privacy-invasive via device identifiers like IDFA/GAID/cookies that build third-party graphs for ad targeting. Topics API, however, is inherently probabilistic and decentralized: it runs in your browser and does not aggregate up to a massive database in the cloud.
Why does this web-centric new ad targeting methodology matter to mobile marketers, who are trying to build apps via mobile user acquisition?
Simple: it matters for mobile marketers because web-to-app is increasingly a valid, inexpensive, and successful user-acquisition vector. And, who knows … something like this or built together with this could hit a privacy-safe version of mobile app marketing on Android at some point, if it’s successful and gets implemented.
And, it’s from Google.
Any new policy or proposal for marketing and advertising by Google is inherently interesting and relevant to marketers, given Google’s massive position as one of the two biggest global players in adtech.
So: I’m going to go through the API, and I’m going to do this piece by piece: bits of text from the API documentation with commentary. (By the way, if I’m an idiot and said something stupid, let me know! We’re smarter together.)
Topics API is interest-based
“With the upcoming removal of third-party cookies on the web, key use cases that browsers want to support will need to be addressed with new APIs. One of those use cases is interest-based advertising.”
The focus here is interest-based advertising. That has usually been inferred from context or devised via digital stalking. But this is better than context, because context is a point-in-time snapshot with a limited perspective. Interests are longer-term, and the Topics API will offer more than just one interest over time.
Important note: this is not intent, and that’s a big deal.
Intent grew significantly in 2021 in response to the deprecation of the IDFA and the ongoing prevalence of privacy, because it’s highly predictive of future activity, including economic activity. That’s still the province, mainly, of search engines.
But Topics API is not very granular
“The intent of the Topics API is to provide callers (including third-party ad-tech or advertising providers on the page that run script) with coarse-grained advertising topics that the page visitor might currently be interested in. These topics will supplement the contextual signals from the current page and can be combined to help find an appropriate advertisement for the visitor.”
This is not granular at all. In fact, it’s very coarse-grained.
We’re talking 350 topics initially, which is tiny. For reference, the IAB Taxonomy is 1500 terms, and even that is really, really limited compared to a somewhat-complete taxonomy which might have hundreds of thousands of terms.
Here’s Google’s comparison of cookies versus topics:
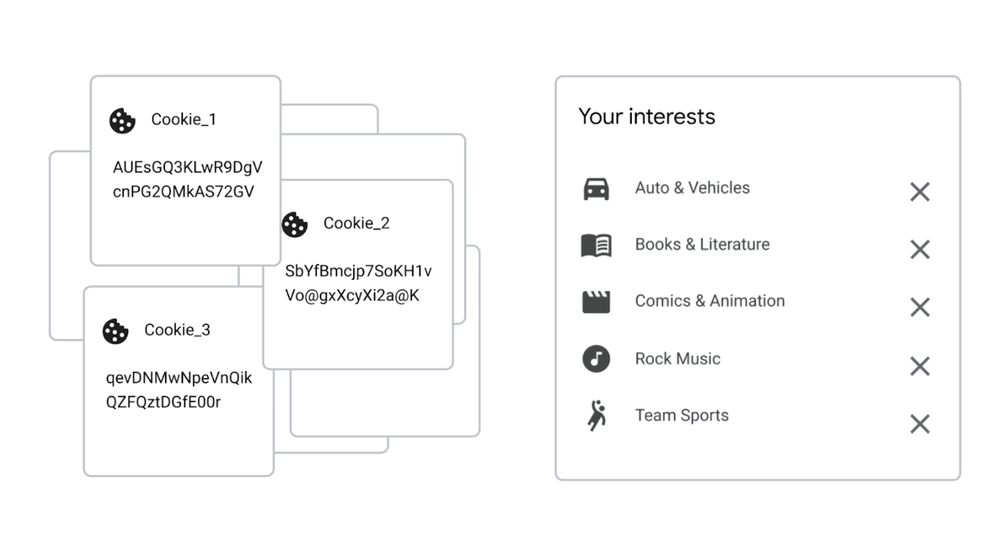
All of those topics are entire worlds in and of themselves. Such as sports: which one? Baseball, hockey, rugby? How about toe wrestling (yes, it exists)? Or ostrich racing? And even if you can narrow a sports topic down to baseball, marketers need to know which teams matter to a person to get really actionable.
In short: we need a lot more refinement here to be useful for marketers. Interestingly, FLoC had more options and more precision …
There could be public mapping of websites to topics
“The topics will be inferred by the browser. The browser will leverage a classifier model to map site hostnames to topics. The classifier weights will be public, perhaps built by an external partner, and will improve over time. It may make sense for sites to provide their own topics …”
There’s a classifier model which will either be built by Google or a third party to tell a browser, and therefore also the Topics API, what a website is about. Those weights are public, and some sites will weigh heavier in the Topics algorithm?
But … weights being public doesn’t mean the model is.
There will be limited learning
“document.browsingTopics() returns an array of up to three topics, one from each of the preceding three epochs (weeks). The returned array is in random order. By providing three topics, infrequently visited sites will have enough topics to find relevant ads, but sites visited weekly will learn at most one new topic per week.”
Third-party cookies are going away, and for good reason. But from a marketer’s perspective you could get a significant amount of data for ad targeting from them. Google’s Topics API, if implemented, will not provide a whole series of interests to a website, just one new topic a week.
And, by the way, topics are only kept for three weeks.
Plus, Google will introduce noise into the signal
“For each week, the user’s top 5 topics are calculated using browsing information local to the browser. One additional topic, chosen uniformly at random, is appended for a total of 6 topics associated with the user for that week/epoch. When document.browsingTopics() is called, the topic for each week is chosen from the 6 available topics as follows: There is a 5% chance that the random topic is returned.”
There’s now a chance of getting spurious data. One in five of the top five topics is randomly generated, and it has a 5% chance of being the one you get when you call the Topics API. In other words, if you’re building your own device graph of some sort, it won’t have super-clean data.
That said … a 5% chance of random data is not much randomization.
Targeting data will be repetitive
“Whatever topic is returned, will continue to be returned for any caller on that site for the remainder of the three weeks.”
You got “sports” on day one? You get “sports” on day 21.
It’s kind of Henry Ford-esque: you can get any color you want as long as it’s the one you got before.
Networks of sites won’t be super-effective at fingerprinting
“The reason that each site gets one of several topics is to ensure that different sites often get different topics, making it harder for sites to cross-correlate the same user.”
You won’t be able to own 35 different websites and build out a deterministic identity graph of your visitors across all of them. Having the ability to actually own 35 websites is not, of course, the reality of most brands or websites, but this essentially means that third-party plugins designed to create device or identity graphs across thousands or even millions of websites will fail.
Or at least have a significantly harder job.
Ouch: you can only learn what you already know (unless you’re an ad network)
Not every API caller will receive a topic. Only callers that observed the user visit a site about the topic in question within the past three weeks can receive the topic. If the caller (specifically the site of the calling context) did not call the API in the past for that user on a site about that topic, then the topic will not be included in the array returned by the API.
Google’s example on this says that the only parties that can get a topic back from the Topics API are those that have previously called the Topics API on a site with a pre-defined and matching site topic.
(If you think that’s confusing, I think you’re right.)
Here’s how Google explains it:
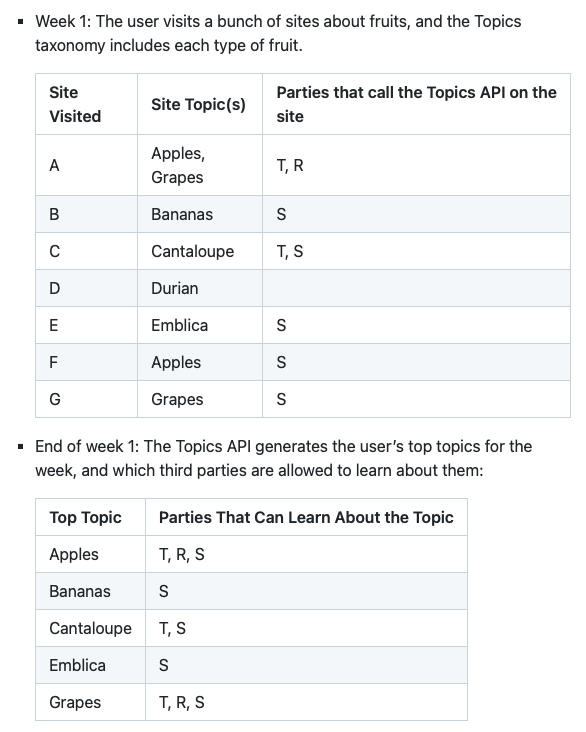
So if in a theoretical week one the Topics API does not fire on a site with a listed topic of X, that site can’t get topic X back from a repeat visitor in week 2.
I guess this means publishers and adtech vendors need to fire the Topics API as much as possible on as many topics as possible in order to get as much targeting data as possible. Clearly, this also means that for frequent and returning users that you track in any other way (account, fingerprinting, magic) you can only learn from Topics API what you already know from other sources.
There is one other twist: in the Topics API ecosystem, you can legally and ethically share those topics with third parties like ad networks and exchanges, which is likely more privacy safe than any other internal methodology. Which one person I’ve chatted with characterizes as by design: publishers don’t know much, if anything, about their users … but the adtech tools for targeting/buy/selling/delivering ads do.
(Remember first-party data? Work to be attractive enough that users become logged-in members, signing up and signing in.)
Big sites with lots of topics will suffer
“We propose choosing topics of interest based only on website hostnames, rather than additional information like the full URL or contents of visited websites.For example, “tennis.example.com” might have a tennis topic whereas example.com/tennis would only have topics related to the more general example.com.”
Wikipedia will rank for … Wikipedia, I suppose, and ESPN will rank for … ESPN. Alternatively, publishers will have to redo their site structures and URL schemas to be able to fully buy into and benefit from the Topics API, which will be interesting at scale and potentially break many other things.
This is a very odd decision that Google says is justified by privacy considerations. SEO specialists who have observed the ever-increasing trend of zero-click searches might beg to differ.
Google will decide what your site is about
“The mapping of sites to topics is not a secret, and can be called by others just as Chrome does. It would be good if a site could learn what its topics are as well via some external tooling …”
Read the second part of that paragraph: it would be good if you could learn what your topics are. That indicates you are not providing that information in the first place … so Google must be.
Fear not.
Google says later: “The mapping of sites to topics will not always be accurate” but it will have “iterative improvements over time.”
And, to be fair, I guess Google already does determine what your site is about during both web search and ad targeting activities.
Of course, privacy is paramount
“The API must not only significantly reduce the amount of information provided in comparison to cookies, it would also be better to ensure that it doesn’t reveal the information to more interested parties than third-party cookies would.”
And …
“The topics revealed by the API should be significantly less personally sensitive for a user than what could be derived using existing tracking methods.”
Google’s goal is to enable targeting while protecting privacy. The most a site or network could learn about a user would be 15 topics per week, Google says, which is significantly less data than third-party cookies currently reveal.
Great in theory … but we’ll have to see if it actually succeeds at either in practice.
One thing the Topics API will do that third-party cookies don’t is tell you that a topic you get for a person is one of their top five browsing topics for the week. In addition, sites that have a persistent relationship with someone will get more data. “As a site calls the API for the same user on the same site over time, they will develop a list of topics that are relevant to that user,” Google says. “That list of topics may have unintended correlations to sensitive topics.”
However it is probabilistic and generic: both significant differences from third-party cookies.
And, it’s important to note, there is transparency: we can all see what topics we’ve been assigned, we can remove ones we don’t like, and we can completely opt out if we so choose. That kind of individual, personal control is refreshing.
Summing up: Topics API is coming
FLoC is dead. Topics API is the new plan, and I can’t see Google killing two proposals in a row. So I assume they’re pretty serious about this one. But … making it feasible will require a lot of work from the adtech and publisher communities, not just Google. And even then, there will be major challenges with ad targeting, marketing measurement, and ad monetization.
We’ve seen this story before: iOS 14.5.
Essentially, almost no-one takes it seriously until it happens, then everyone panics. Spend flees to more targetable and measurable ecosystems (how happy do you think Facebook is about this?) while everyone works it out and builds new tech (or old tech, like fingerprinting) to try to circumvent the new privacy-centric features.
After six to nine months of arms race, we’re back to life as somewhat normal.
We can help
Working on marketing measurement? Web to app? Mobile-first? Need a full suite of data from cost to attribution to modeling to probabilistic? Singular can help.

Stay up to date on the latest happenings in digital marketing

